
Machine learning models play a pivotal role in modern healthcare, transforming everything from diagnostic imaging to enabling of predictions for patient outcomes. These models may not only enhance diagnostic precision across various data types, including medical imaging and electronic health records, but could also tailor treatment plans by sifting through complex layers of patient data. Beyond diagnostics, they could offer personalized treatment recommendations by analyzing vast amounts of data, including electronic health records and genetic information. This technology could not only enable more accurate predictions of patient outcomes but also pave the way for personalized medicine and efficient healthcare delivery, marking a significant leap forward in patient care and medical research.
A common challenge in leveraging machine learning models in healthcare is that not all data enhances model performance equally. The selection of data for training these models is as crucial as the algorithmic architecture of the model itself. This issue underscores the problem of "garbage in, garbage out," where the quality and relevance of input data directly impact the accuracy and reliability of the model's output. Inaccurate, incomplete, or irrelevant data can lead to misleading results, compromising patient care and leading to potential misdiagnoses. Hence, meticulous data curation and selection are essential to ensure that these models can truly benefit healthcare delivery and patient outcomes.
The core idea: Influence-based data selection
Traditionally, enhancing machine learning model performance focused on two main strategies: modifying the model's architecture and refining the training algorithms. Adjusting the model's structure, such as its layers and connections, can improve its ability to learn from data. On the other hand, refining training algorithms, including optimization techniques and learning rates, aims to make learning more efficient and effective. These approaches require deep technical knowledge and can increase computational demands.
GE HealthCare’s recent research collaboration work* pivots the focus towards the training data itself, rather than just the model architecture or the algorithms. This work introduces a method for assessing which data samples most positively or negatively influence a model's performance. Rooted in influence-based data selection, this approach underscores the pivotal role that training data selection plays in the utility, fairness, and robustness of machine learning models. By pinpointing and utilizing the most beneficial data samples for training, the research proposes a new avenue for enhancing model performance that complements the traditional strategies discussed in section.
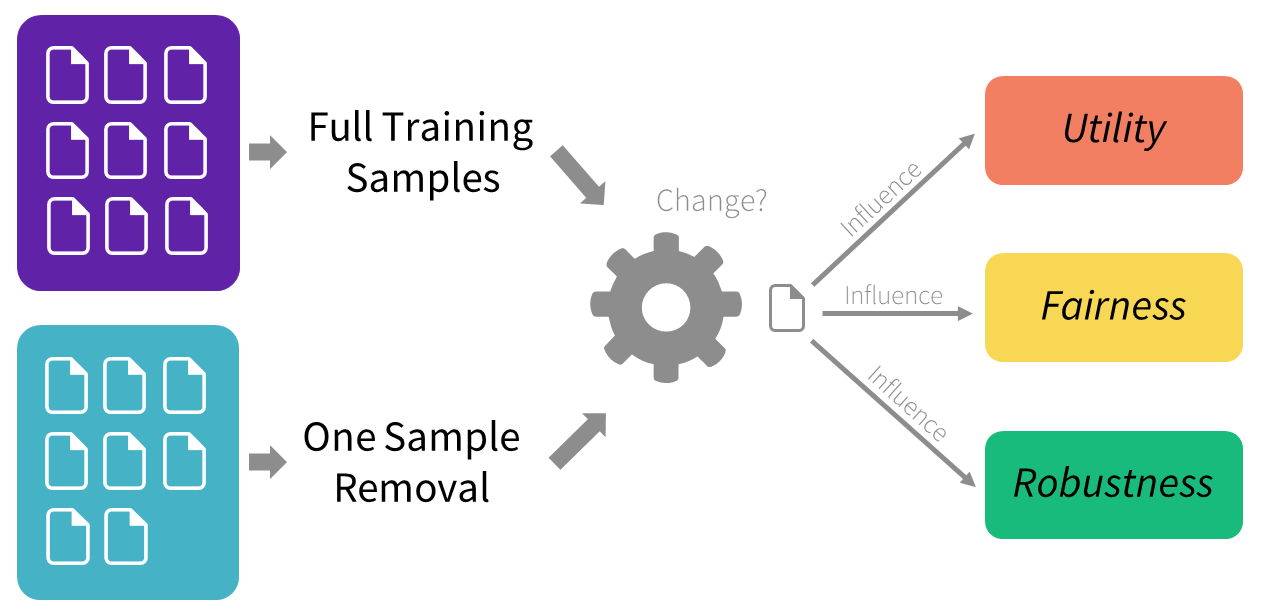
It introduces a method to assess which data samples most positively or negatively influence a model's performance. This approach, rooted in influence functions, a statistical tool to characterize the counterfactual effect of training data removal, recognizes the significant impact that the choice of training data can have on the accuracy, fairness, and robustness of machine learning models. This proposed approach offers a fast approximation to evaluate each training sample at scale and provides intuitive insights for samples to be fit by a model. By identifying and selecting the most beneficial data samples for training and interpreting the data selection as a decision tree, the research suggests a novel path to enhancing model performance that complements traditional strategies.
"Influence-based data selection" is like sifting through a pile of puzzle pieces to find the ones that fit perfectly, helping complete the picture more effectively. In machine learning, this method helps identify which pieces of data (or information) are the most useful for training a model, ensuring it performs better in tasks such as making accurate predictions, being fair across different groups of people, and standing strong against misleading information. Essentially, it's about picking the best ingredients to improve the recipe for a model's success.
Why selection matters in healthcare data models
Just as a doctor carefully selects the most informative tests and patient history to accurately diagnose a condition, the concept of influence-based data selection sifts through vast datasets to find the data points that best improve a machine learning model's performance. This careful selection process in medicine is mirrored in the method proposed in the paper, aiming to enhance model accuracy, fairness, and robustness.
In healthcare, the accuracy of a diagnosis can significantly impact patient treatment and prognosis. Similarly, the performance of a machine learning model—its ability to make correct predictions—is crucial in applications ranging from patient care to research. Just as precise and thoughtful selection of tests and data ensures diagnostic accuracy in healthcare, selecting the right data points for model training optimizes performance.
Moreover, just like healthcare professionals strive for fairness and robustness in diagnosing and treating patients from diverse backgrounds, machine learning models must perform equitably across different groups and remain reliable under various conditions. Fairness ensures that no group is systematically disadvantaged by a model's predictions, paralleling the medical principle of providing equitable treatment to all patients. Robustness in a model, similar to the reliability of medical diagnostics across rare or atypical cases, ensures that the model's performance is stable and reliable, even when faced with challenging or unexpected data.
In both domains, the goal is to make the most informed, accurate, and fair decisions possible, whether determining a patient's treatment plan or making predictions with a machine learning model. The paper's focus on influence-based data selection introduces a method comparable to the diagnostic process in medicine, emphasizing the importance of choosing the right information to improve outcomes, be it patient health or model performance.
Key findings and techniques
This research introduces two straightforward yet powerful algorithms, designed to refine how machine learning models learn by focusing on the data they're trained on:
- Estimating the influence of data samples: Imagine you're sorting through a stack of photographs, trying to decide which ones tell the best story for your photo album. Similarly, the first algorithm sifts through all the data a model has been trained on, evaluating each piece to determine its impact on the model's performance. It identifies which data samples are like the photos that enhance your album—those that positively influence the model, making it smarter and more accurate.
- Trimming less helpful data: Continuing with the photo album analogy, once you've identified the most meaningful photos, you might remove the ones that don't add value or might even spoil the story you're trying to convey. The second algorithm does something similar for machine learning models. It systematically removes the data that doesn't help—or might even hinder—the model's learning process. This "trimming" ensures the model focuses only on the most beneficial data, leading to improvements in accuracy, fairness, and the ability to withstand misleading information.
Together, these algorithms offer a novel approach to enhancing model performance by carefully selecting the training data, akin to curating the best collection of photos for your album, ensuring the final outcome is both beautiful and meaningful.
This research demonstrates remarkable success across a variety of challenging scenarios that have direct implications for healthcare:
- Combating data poisoning: Just as doctors must ensure the accuracy of medical records and test results to treat patients effectively, machine learning models need representative, reliable data. The research showed success in identifying and removing "poisoned" data—incorrect or misleading information that could skew the model's learning process. In healthcare, this could translate to ensuring that robust diagnostic models are trained on accurate patient data, mitigating the risk of misdiagnoses due to errors in patient records or lab results.
- Adapting to new, unseen data: The algorithms proved effective in adapting models to new and unseen data, similar to how the medical field must rapidly respond to emerging diseases. This ability to adjust to new information ensures that machine learning models, like medical professionals, can remain effective even as the landscape changes—be it a novel pathogen or a previously unknown genetic marker for a disease.
These successes underscore the potential for applying these algorithms to healthcare, where they could help develop diagnostic tools that remain accurate in the face of evolving diseases but also fair and equitable across diverse patient populations. By ensuring that models are trained on the most relevant and high-quality data, healthcare professionals could better predict patient outcomes, tailor treatments to individual needs, and work towards eliminating disparities in health outcomes among different demographic groups.
Future practical applications in medicine
The methodologies discussed in the research paper have the potential to significantly enhance healthcare through machine learning, particularly in improving diagnostic model accuracy. This could lead to earlier and more precise detection of diseases, positively impacting treatment outcomes. Furthermore, the approach opens doors to personalized medicine, allowing for treatments tailored to individual patient profiles based on genetic markers or lifestyle factors. Additionally, it could streamline the design of clinical trials, making them more efficient and effective by focusing on the most relevant participant data. Together, these advancements promise a future where healthcare could be more accurate, personalized, and efficient, transforming patient care and treatment methodologies.
The approach outlined in the paper, focusing on selecting the most informative and diverse data for training machine learning models, naturally leads to more reliable and robust models. This aspect is particularly crucial in healthcare, where data variability across populations can significantly impact model performance. By carefully curating training datasets to include a wide range of data points from different demographics, health conditions, and genetic backgrounds, models can learn to generalize better across the diverse spectrum of patients they will encounter in real-world settings. This method could help ensure that the models are not only accurate in their predictions but also fair and unbiased, providing equitable healthcare outcomes for all patient groups. It has been shown that the inclusion of diverse and informative data helps models to adapt more effectively to new, unseen data, enhancing their reliability in diagnosing emerging diseases or rare conditions. In essence, this data-centric approach paves the way for healthcare models that are more inclusive, adaptable, and ultimately more effective in delivering personalized patient care.
Looking ahead: machine learning models in healthcare
Further research is essential to tailor these findings more directly to healthcare applications, bridging the gap between theoretical models and practical medical use. This exploration can refine how machine learning models handle the unique complexities and variances within healthcare data, leading to advancements in diagnostic accuracy, treatment personalization, and overall patient care. Such efforts promise to unlock the full potential of these methodologies in improving health outcomes and advancing medical science.
Encouraging collaboration between machine learning researchers and medical professionals is pivotal to exploring this new frontier. By working together, they can combine their expertise to tailor machine learning methodologies directly to healthcare needs, ensuring that advances in AI and data science translate into tangible improvements in patient care. This collaborative approach can accelerate the development of innovative solutions that are both technically sound and clinically relevant, driving forward the integration of cutting-edge technology into everyday medical practice.
Conclusion
The potential of influence-based data selection to transform healthcare AI is immense, particularly in enhancing the performance of diagnostic models. By pinpointing the most impactful data for training, this approach has the potential to improve the accuracy, fairness, and robustness of models used in medical diagnostics. Such advancements are necessary to deliver on the promise of early detection of diseases, more personalized treatment plans, and equitable healthcare outcomes across diverse patient populations, showcasing the transformative power of this methodology in revolutionizing patient care through technology.
Learn more about GE HealthCare's AI research here:
SonoSAM, pioneering research analysis of AI in ultrasound imaging
*Research conducted in collaboration with Anshuman Chhabra and Hongfu Liu.